mirror of https://github.com/CIRCL/lookyloo
chg: Update readme to point to the website
parent
bc4cf6a3a5
commit
6066bb1a4c
148
README.md
148
README.md
|
|
@ -1,16 +1,15 @@
|
|||

|
||||
[](https://www.lookyloo.eu/docs/main/index.html)
|
||||
|
||||
[](https://gitter.im/lookyloo-app/community)
|
||||
|
||||
*Lookyloo* is a web interface allowing to scrape a website and then displays a
|
||||
tree of domains calling each other.
|
||||
*[Lookyloo](https://www.lookyloo.eu/docs/main/index.html)* is a web interface allowing
|
||||
to scrape a website and then displays a tree of domains calling each other.
|
||||
|
||||
Thank you very much [Tech Blog @ willshouse.com](https://techblog.willshouse.com/2012/01/03/most-common-user-agents/)
|
||||
for the up-to-date list of UserAgents.
|
||||
|
||||
# What is that name?!
|
||||
|
||||
|
||||
```
|
||||
1. People who just come to look.
|
||||
2. People who go out of their way to look at people or something often causing crowds and more disruption.
|
||||
|
|
@ -21,147 +20,24 @@ In L.A. usually the lookyloo's cause more accidents by not paying full attention
|
|||
|
||||
Source: [Urban Dictionary](https://www.urbandictionary.com/define.php?term=lookyloo)
|
||||
|
||||
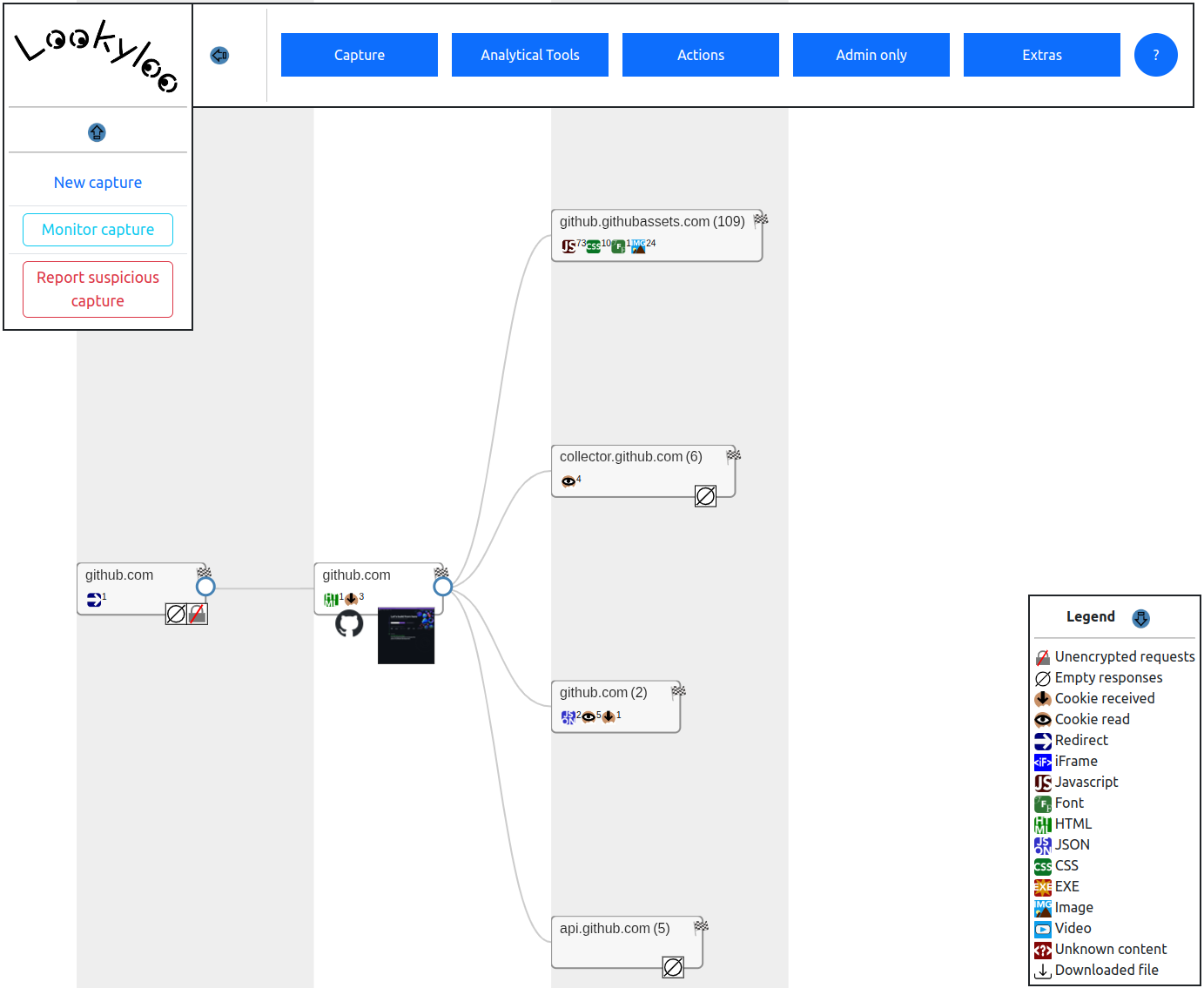
# Screenshot
|
||||
# No, really, what is Lookyloo?
|
||||
|
||||

|
||||
Find all you need to know about Lookyloo [on the website](https://www.lookyloo.eu/docs/main/index.html).
|
||||
|
||||
# Implementation details
|
||||
|
||||
This code is very heavily inspired by [webplugin](https://github.com/etetoolkit/webplugin) and adapted to use flask as backend.
|
||||
|
||||
The two core dependencies of this project are the following:
|
||||
|
||||
* [ETE Toolkit](http://etetoolkit.org/): A Python framework for the analysis and visualization of trees.
|
||||
* [Splash](https://splash.readthedocs.io/en/stable/): Lightweight, scriptable browser as a service with an HTTP API
|
||||
|
||||
# Cookies
|
||||
|
||||
If you want to scrape a website as if you were loggged in, you need to pass your sessions cookies.
|
||||
You can do it the the folloing way:
|
||||
|
||||
1. Install [Cookie Quick Manager](https://addons.mozilla.org/en-US/firefox/addon/cookie-quick-manager/)
|
||||
2. Click onthe icon in the top right of your browser > Manage all cookies
|
||||
3. Search for a domain, tick the Sub-domain box if needed
|
||||
4. Right clock on the domain you want to export > save to file > $LOOKYLOO_HOME/cookies.json
|
||||
|
||||
Then, you need to restart the webserver and from now on, every cookies you have in that file will be available for the browser used by Splash
|
||||
|
||||
# Python client
|
||||
|
||||
You can use `pylookyloo` as a standalone script, or as a library, [more details here](https://github.com/Lookyloo/lookyloo/tree/master/client)
|
||||
|
||||
|
||||
# Installation
|
||||
|
||||
**IMPORTANT**: Use [poetry](https://github.com/python-poetry/poetry/#installation)
|
||||
Please refer to the [install guide](https://www.lookyloo.eu/docs/main/install-lookyloo.html).
|
||||
|
||||
**NOTE**: Yes, it requires python3.7+. No, it will never support anything older.
|
||||
# Python client
|
||||
|
||||
**NOTE**: If you want to run a public instance, you should set `only_global_lookups=True`
|
||||
in `website/web/__init__.py` and `bin/async_scrape.py` to disallow scraping of private IPs.
|
||||
`pylookyloo` is the recommended client to interact with a Lookyloo instance.
|
||||
|
||||
## Installation of Splash
|
||||
|
||||
You need a running splash instance, preferably on [docker](https://splash.readthedocs.io/en/stable/install.html)
|
||||
It is avaliable on PyPi, so you can install it this way:
|
||||
|
||||
```bash
|
||||
sudo apt install docker.io
|
||||
sudo docker pull scrapinghub/splash
|
||||
sudo docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash --disable-browser-caches
|
||||
# On a server with a decent abount of RAM, you may want to run it this way:
|
||||
# sudo docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash -s 100 -m 50000 --disable-browser-caches
|
||||
pip install pylookyloo
|
||||
```
|
||||
|
||||
## Install redis
|
||||
|
||||
```bash
|
||||
git clone https://github.com/antirez/redis.git
|
||||
cd redis
|
||||
git checkout 5.0
|
||||
make
|
||||
cd ..
|
||||
```
|
||||
|
||||
## Installation of Lookyloo
|
||||
|
||||
```bash
|
||||
git clone https://github.com/Lookyloo/lookyloo.git
|
||||
cd lookyloo
|
||||
poetry install
|
||||
echo LOOKYLOO_HOME="'`pwd`'" > .env
|
||||
poetry run update
|
||||
```
|
||||
|
||||
# Run the app
|
||||
|
||||
```bash
|
||||
poetry run start
|
||||
```
|
||||
|
||||
# Run the app in production
|
||||
|
||||
## With a reverse proxy (Nginx)
|
||||
|
||||
```bash
|
||||
pip install uwsgi
|
||||
```
|
||||
|
||||
## Config files
|
||||
|
||||
You have to configure the two following files:
|
||||
|
||||
* `etc/nginx/sites-available/lookyloo`
|
||||
* `etc/systemd/system/lookyloo.service`
|
||||
|
||||
Copy them to the appropriate directories, and run the following command:
|
||||
```bash
|
||||
sudo ln -s /etc/nginx/sites-available/lookyloo /etc/nginx/sites-enabled
|
||||
```
|
||||
|
||||
If needed, remove the default site
|
||||
```bash
|
||||
sudo rm /etc/nginx/sites-enabled/default
|
||||
```
|
||||
|
||||
Make sure everything is working:
|
||||
|
||||
```bash
|
||||
sudo systemctl start lookyloo
|
||||
sudo systemctl enable lookyloo
|
||||
sudo nginx -t
|
||||
# If it is cool:
|
||||
sudo service nginx restart
|
||||
```
|
||||
|
||||
And you can open ```http://<IP-or-domain>/```
|
||||
|
||||
Now, you should configure [TLS (let's encrypt and so on)](https://www.digitalocean.com/community/tutorials/how-to-secure-nginx-with-let-s-encrypt-on-ubuntu-16-04)
|
||||
|
||||
# Use aquarium for a reliable multi-users app
|
||||
|
||||
Aquarium is a haproxy + splash bundle that will allow lookyloo to be used by more than one user at once.
|
||||
|
||||
The initial version of the project was created by [TeamHG-Memex](https://github.com/TeamHG-Memex/aquarium) but
|
||||
we have a [dedicated repository](https://github.com/Lookyloo/aquarium) that fits our needs better.
|
||||
|
||||
Follow [the documentation](https://github.com/Lookyloo/aquarium/blob/master/README.rst) if you want to use it.
|
||||
|
||||
|
||||
# Run the app with a simple docker setup
|
||||
|
||||
## Dockerfile
|
||||
The repository includes a [Dockerfile](Dockerfile) for building a containerized instance of the app.
|
||||
|
||||
Lookyloo stores the scraped data in /lookyloo/scraped. If you want to persist the scraped data between runs it is sufficient to define a volume for this directory.
|
||||
|
||||
## Running a complete setup with Docker Compose
|
||||
Additionally you can start a complete setup, including the necessary Docker instance of splashy, by using
|
||||
Docker Compose and the included service definition in [docker-compose.yml](docker-compose.yml) by running
|
||||
|
||||
```
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
After building and startup is complete lookyloo should be available at [http://localhost:5000/](http://localhost:5000/)
|
||||
|
||||
If you want to persist the data between different runs uncomment the "volumes" definition in the last two lines of
|
||||
[docker-compose.yml](docker-compose.yml) and define a data storage directory in your Docker host system there.
|
||||
Find more details [here](https://www.lookyloo.eu/docs/main/pylookyloo-overview.html).
|
||||
|
|
|
|||
Loading…
Reference in New Issue