|
|
||
|---|---|---|
| .github | ||
| bin | ||
| cache | ||
| config | ||
| contributing | ||
| doc | ||
| etc | ||
| full_index | ||
| indexing | ||
| known_content | ||
| known_content_user | ||
| logs | ||
| lookyloo | ||
| tools | ||
| user_agents | ||
| website | ||
| .dockerignore | ||
| .gitignore | ||
| .pre-commit-config.yaml | ||
| Dockerfile | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| code_of_conduct.md | ||
| docker-compose.yml | ||
| mypy.ini | ||
| poetry.lock | ||
| pyproject.toml | ||
README.md
Lookyloo is a web interface that captures a webpage and then displays a tree of the domains, that call each other.

What's in a name?!
Lookyloo ...
Same as Looky Lou; often spelled as Looky-loo (hyphen) or lookylou
1. A person who just comes to look.
2. A person who goes out of the way to look at people or something, often causing crowds and disruption.
3. A person who enjoys watching other people's misfortune. Oftentimes car onlookers that stare at a car accidents.
In L.A., usually the lookyloos cause more accidents by not paying full attention to what is ahead of them.
Source: Urban Dictionary
No, really, what is Lookyloo?
Lookyloo is a web interface that allows you to capture and map the journey of a website page.
Find all you need to know about Lookyloo on our documentation website.
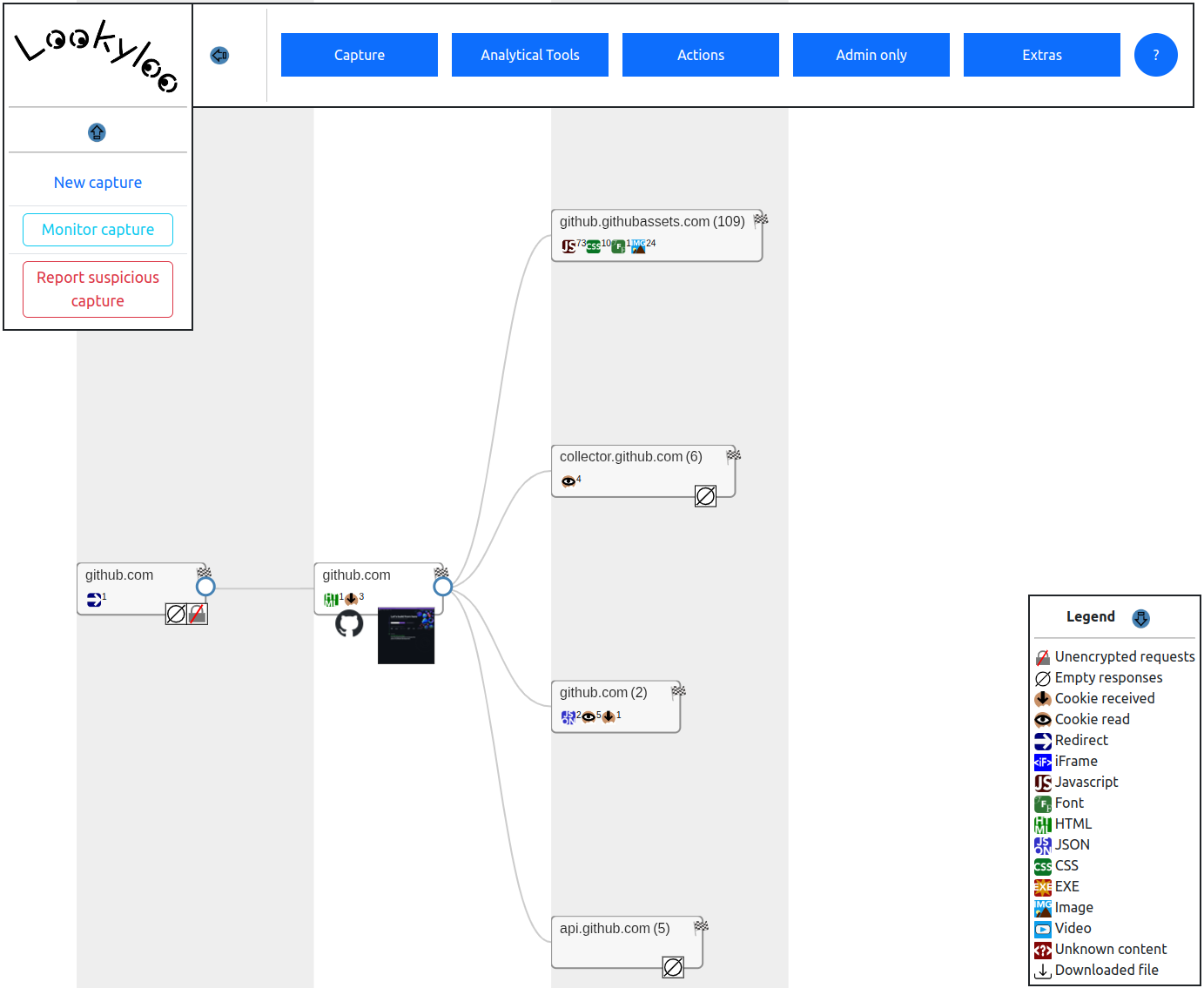
Here's an example of a Lookyloo capture of the site github.com
REST API
The API is self documented with swagger. You can play with it on the demo instance.
Installation
Please refer to the install guide.
Python client
pylookyloo is the recommended client to interact with a Lookyloo instance.
It is avaliable on PyPi, so you can install it using the following command:
pip install pylookyloo
For more details on pylookyloo, read the overview docs, the documentation of the module itself, or the code in this GitHub repository.
Notes regarding using S3FS for storage
Directory listing
TL;DR: it is slow.
If you have namy captures (say more than 1000/day), and store captures in a s3fs bucket mounted with s3fs-fuse,
doing a directory listing in bash (ls) will most probably lock the I/O for every process
trying to access any file in the whole bucket. The same will be true if you access the
filesystem using python methods (iterdir, scandir...))
A workaround is to use the python s3fs module as it will not access the filesystem for listing directories.
You can configure the s3fs credentials in config/generic.json key s3fs.
Warning: this will not save you if you run ls on a directoy that contains a lot of captures.
Versioning
By default, a MinIO bucket (backend for s3fs) will have versioning enabled, wich means it keeps a copy of every version of every file you're storing. It becomes a problem if you have a lot of captures as the index files are updated on every change, and the max amount of versions is 10.000. So by the time you have > 10.000 captures in a directory, you'll get I/O errors when you try to update the index file. And you absolutely do not care about that versioning in lookyloo.
To check if versioning is enabled (can be either enabled or suspended):
mc version info <alias_in_config>/<bucket>
The command below will suspend versioning:
mc version suspend <alias_in_config>/<bucket>
I'm stuck, my file is raising I/O errors
It will happen when your index was updated 10.000 times and versioning was enabled.
This is how to check you're in this situation:
- Error message from bash (unhelpful):
$ (git::main) rm /path/to/lookyloo/archived_captures/Year/Month/Day/index
rm: cannot remove '/path/to/lookyloo/archived_captures/Year/Month/Day/index': Input/output error
- Check with python
from lookyloo.default import get_config
import s3fs
s3fs_config = get_config('generic', 's3fs')
s3fs_client = s3fs.S3FileSystem(key=s3fs_config['config']['key'],
secret=s3fs_config['config']['secret'],
endpoint_url=s3fs_config['config']['endpoint_url'])
s3fs_bucket = s3fs_config['config']['bucket_name']
s3fs_client.rm_file(s3fs_bucket + '/Year/Month/Day/index')
- Error from python (somewhat more helpful):
OSError: [Errno 5] An error occurred (MaxVersionsExceeded) when calling the DeleteObject operation: You've exceeded the limit on the number of versions you can create on this object
- Solution: run this command to remove all older versions of the file
mc rm --non-current --versions --recursive --force <alias_in_config>/<bucket>/Year/Month/Day/index
Contributing to Lookyloo
To learn more about contributing to Lookyloo, see our contributor guide.
Code of Conduct
At Lookyloo, we pledge to act and interact in ways that contribute to an open, welcoming, diverse, inclusive, and healthy community. You can access our Code of Conduct here or on the Lookyloo docs site.
Support
- To engage with the Lookyloo community contact us on Gitter.
- Let us know how we can improve Lookyloo by opening an issue.
- Follow us on Twitter.
Security
To report vulnerabilities, see our Security Policy.
Credits
Thank you very much Tech Blog @ willshouse.com for the up-to-date list of UserAgents.
License
See our LICENSE.