|
|
||
|---|---|---|
| .github/workflows | ||
| bin | ||
| cache | ||
| client | ||
| config | ||
| doc | ||
| etc | ||
| indexing | ||
| lookyloo | ||
| tools | ||
| user_agents | ||
| website | ||
| .dockerignore | ||
| .gitignore | ||
| .travis.yml | ||
| Dockerfile | ||
| LICENSE | ||
| README.md | ||
| SECURITY.md | ||
| code_of_conduct.md | ||
| docker-compose.yml | ||
| poetry.lock | ||
| pyproject.toml | ||
| setup.py | ||
README.md

Lookyloo is a web interface allowing to scrape a website and then displays a tree of domains calling each other.
Thank you very much Tech Blog @ willshouse.com for the up-to-date list of UserAgents.
What is that name?!
1. People who just come to look.
2. People who go out of their way to look at people or something often causing crowds and more disruption.
3. People who enjoy staring at watching other peoples misfortune. Oftentimes car onlookers to car accidents.
Same as Looky Lou; often spelled as Looky-loo (hyphen) or lookylou
In L.A. usually the lookyloo's cause more accidents by not paying full attention to what is ahead of them.
Source: Urban Dictionary
Screenshot
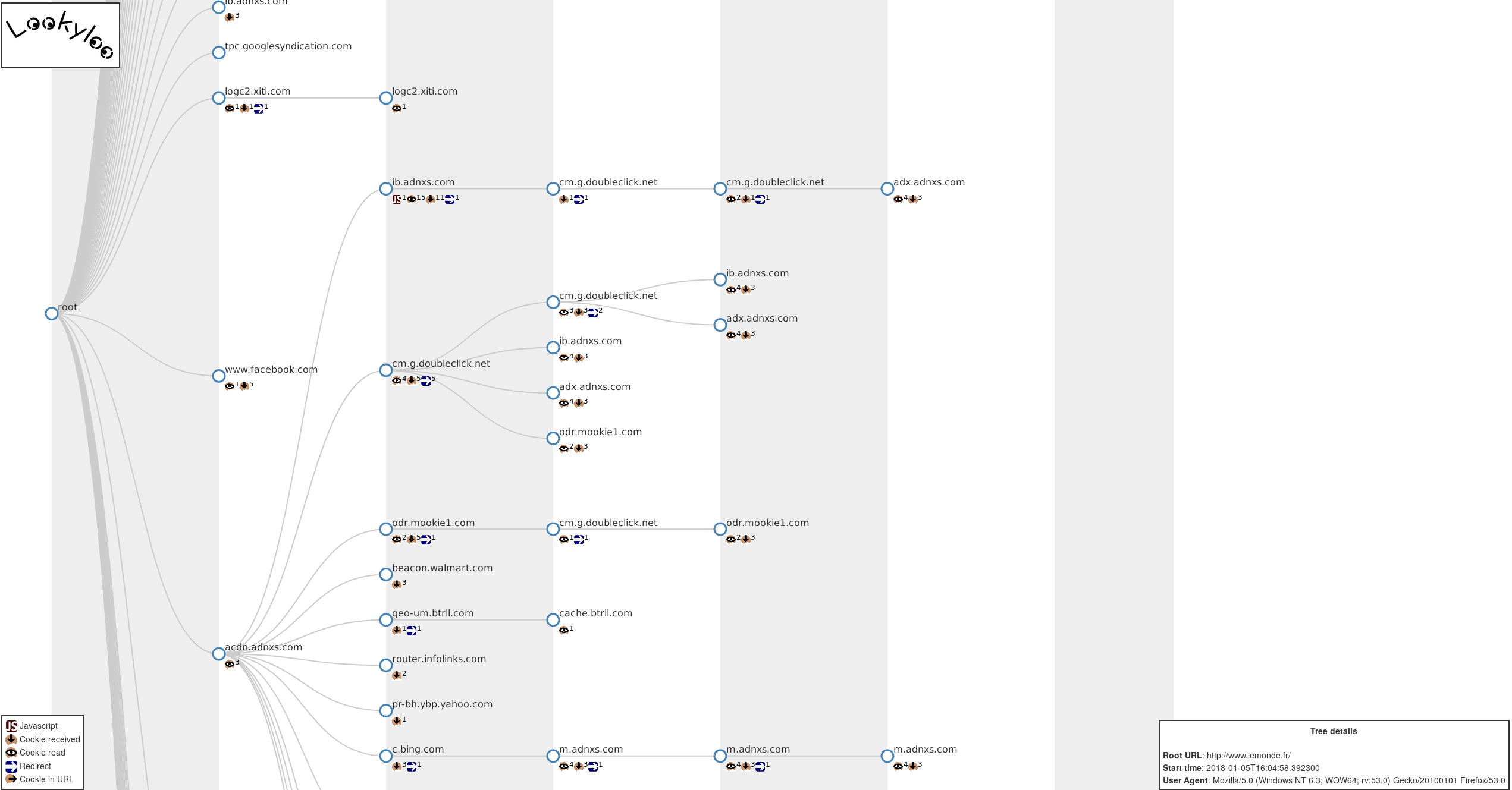
Implementation details
This code is very heavily inspired by webplugin and adapted to use flask as backend.
The two core dependencies of this project are the following:
- ETE Toolkit: A Python framework for the analysis and visualization of trees.
- Splash: Lightweight, scriptable browser as a service with an HTTP API
Cookies
If you want to scrape a website as if you were loggged in, you need to pass your sessions cookies. You can do it the the folloing way:
- Install Cookie Quick Manager
- Click onthe icon in the top right of your browser > Manage all cookies
- Search for a domain, tick the Sub-domain box if needed
- Right clock on the domain you want to export > save to file > $LOOKYLOO_HOME/cookies.json
Then, you need to restart the webserver and from now on, every cookies you have in that file will be available for the browser used by Splash
Python client
You can use pylookyloo as a standalone script, or as a library, more details here
Installation
IMPORTANT: Use poetry
NOTE: Yes, it requires python3.7+. No, it will never support anything older.
NOTE: If you want to run a public instance, you should set only_global_lookups=True
in website/web/__init__.py and bin/async_scrape.py to disallow scraping of private IPs.
Installation of Splash
You need a running splash instance, preferably on docker
sudo apt install docker.io
sudo docker pull scrapinghub/splash
sudo docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash --disable-browser-caches
# On a server with a decent abount of RAM, you may want to run it this way:
# sudo docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash -s 100 -m 50000 --disable-browser-caches
Install redis
git clone https://github.com/antirez/redis.git
cd redis
git checkout 5.0
make
cd ..
Installation of Lookyloo
git clone https://github.com/Lookyloo/lookyloo.git
cd lookyloo
poetry install
echo LOOKYLOO_HOME="'`pwd`'" > .env
Run the app
poetry run start.py
Run the app in production
With a reverse proxy (Nginx)
pip install uwsgi
Config files
You have to configure the two following files:
etc/nginx/sites-available/lookylooetc/systemd/system/lookyloo.service
Copy them to the appropriate directories, and run the following command:
sudo ln -s /etc/nginx/sites-available/lookyloo /etc/nginx/sites-enabled
If needed, remove the default site
sudo rm /etc/nginx/sites-enabled/default
Make sure everything is working:
sudo systemctl start lookyloo
sudo systemctl enable lookyloo
sudo nginx -t
# If it is cool:
sudo service nginx restart
And you can open http://<IP-or-domain>/
Now, you should configure TLS (let's encrypt and so on)
Use aquarium for a reliable multi-users app
Aquarium is a haproxy + splash bundle that will allow lookyloo to be used by more than one user at once.
The initial version of the project was created by TeamHG-Memex but we have a dedicated repository that fits our needs better.
Follow the documentation if you want to use it.
Run the app with a simple docker setup
Dockerfile
The repository includes a Dockerfile for building a containerized instance of the app.
Lookyloo stores the scraped data in /lookyloo/scraped. If you want to persist the scraped data between runs it is sufficient to define a volume for this directory.
Running a complete setup with Docker Compose
Additionally you can start a complete setup, including the necessary Docker instance of splashy, by using Docker Compose and the included service definition in docker-compose.yml by running
docker-compose up
After building and startup is complete lookyloo should be available at http://localhost:5000/
If you want to persist the data between different runs uncomment the "volumes" definition in the last two lines of docker-compose.yml and define a data storage directory in your Docker host system there.